Centre for High performance computing in Cape Town
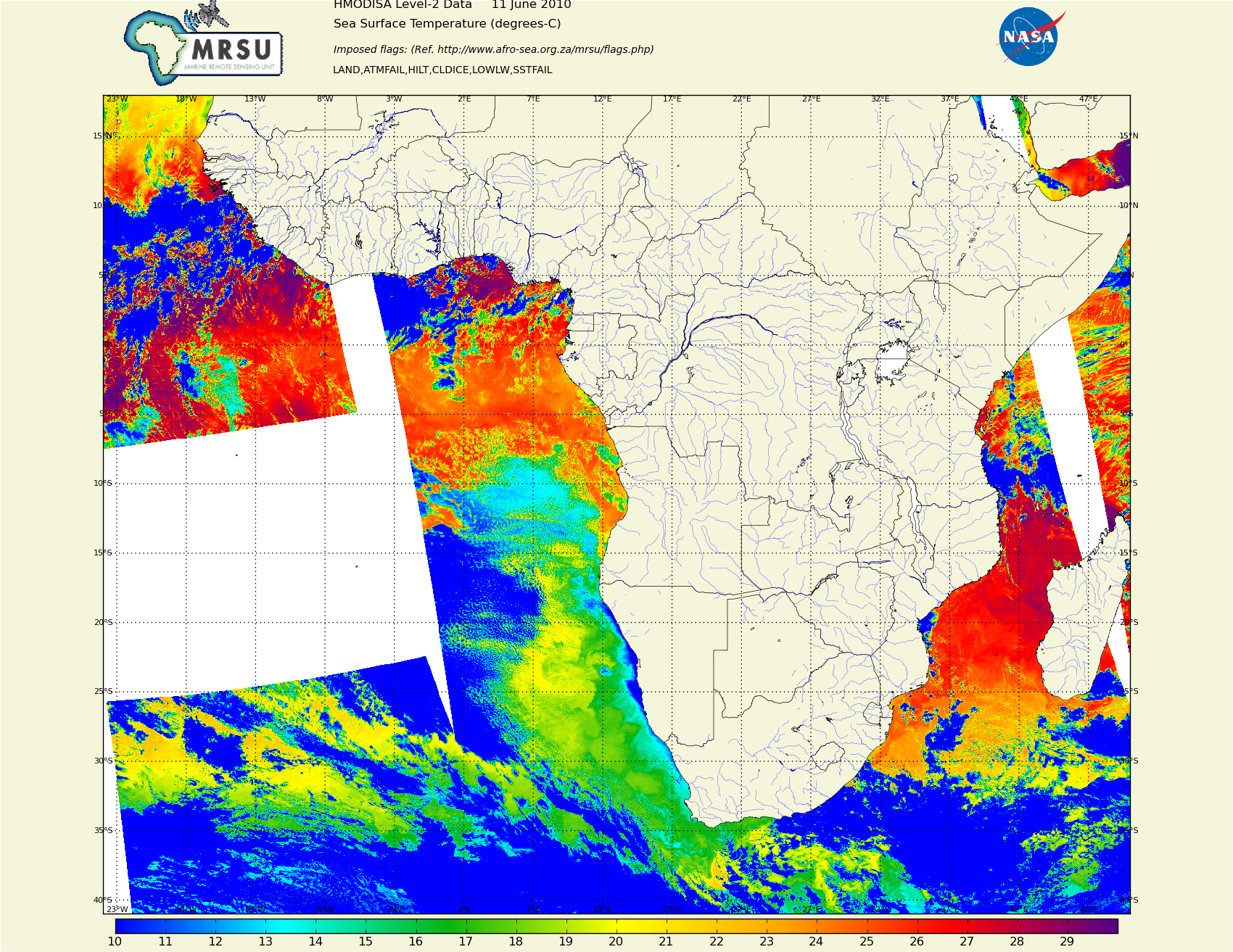
Sea surface temperature around Africa
Last month I started a contracting job with the Marine Remote Sensing Unit - a collaboration between the Centre for High Performance Computing (CHPC) and University of Cape Town.
I have some history in parallel processing, mostly with Inmos, a British microelectronics company that built the Transputer, a ground-breaking microprocessor of the 1980s. I had been looking for an opportunity to work at the CHPC for a while, and took the chance when an opening arrived via the clug-work mailing list run by the Cape Town Linux Users Group.
What is the CHPC ?

Myself and Stewart Bernard in front of the CHPC Sun cluster
Supercomputers these days consist of racks of identically-configured Blades with a fast network switch connecting them together. There is also a filesystem built upon many hard drives, providing redundancy and speed, accessible over the network.
There are two clusters at the CHPC - an IBM e1350 Cluster, iQudu, consisting of 160 compute nodes and 3 storage nodes connected to 94 Terabytes of storage. There is also a Sun Microsystems cluster with 288 blades with 8 cores each and 200 Terabytes of shared storage. This is an announcement of the commissioning of the Sun cluster, and here is a blog post from a Sun engineer. There is also an older IBM Blue Genecluster, built of PowerPC ASICs.
Both clusters run x86_64 Linux, so they appear very similar. There is a certain expectation that you provide your own environment to run your application - they provide development libraries and compilation tools.
The Sun cluster is the more recent, and the one I am using. It uses Lustre as a user filesystem. The nodes boot from Flash, and the core operating system lives in 8Gig flash.
It also has a read-only NFS mount for non-critical code - as some of the 8Gig Flash is used for logspace.
What is Marine Remote Sensing?
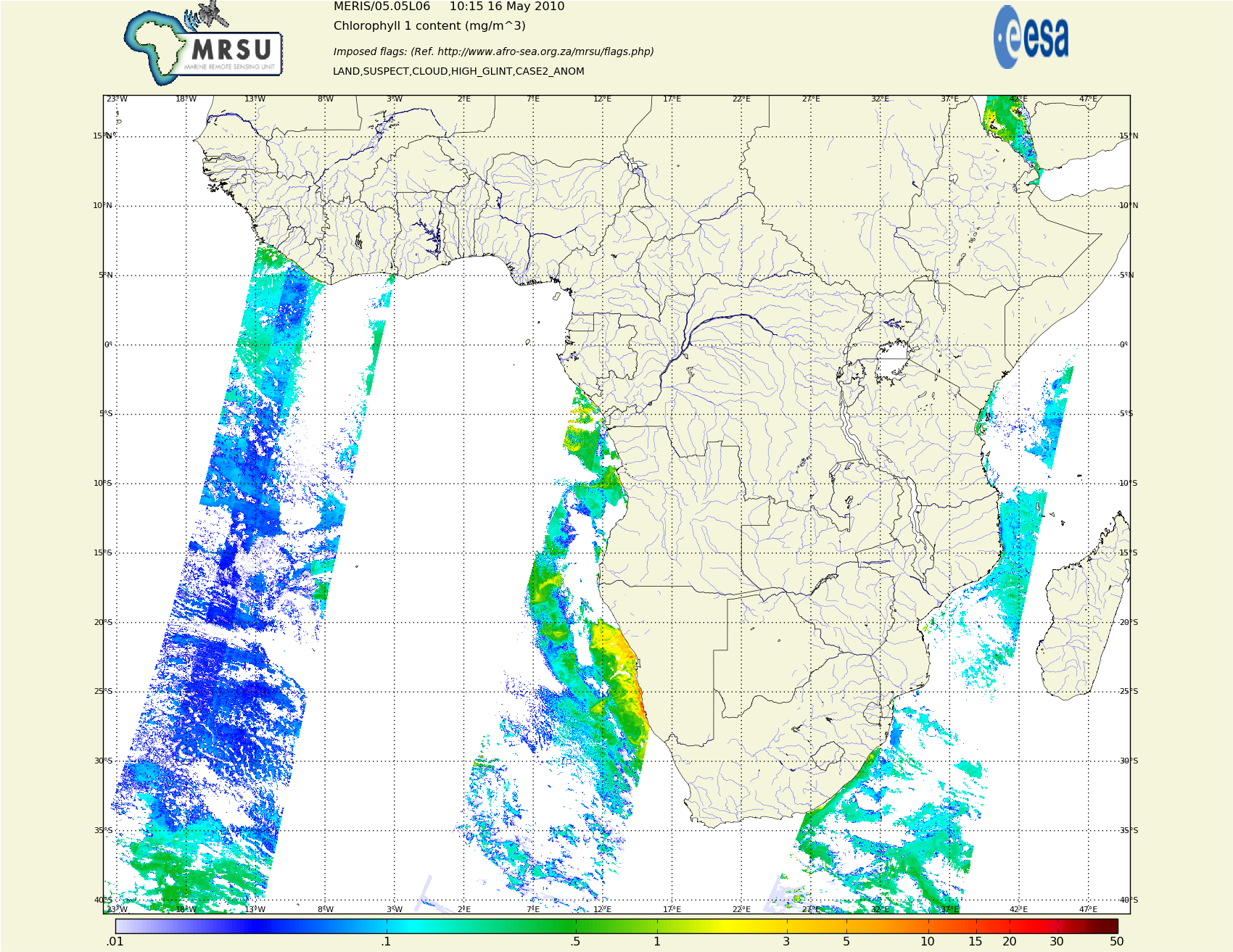
Algae in the sea around Africa
Earth observation satellites travel a polar orbit, with some synchronisation with the earth’s spin. I think it crosses the equator at the same time every day. We use, among others, data from the Envisat satellite. There have been some recent news stories here and here. The satellite images earth as it passes over, onto a linear array of sensors tailored for different frequency bands. All data is publicly available.
We can get the raw level 1 sensor data, in a dozen or so different spectral bands, or ESA will crunch a few helpful numbers that will indicate algal bloom, turbidity, sea surface temperature, vegetation etc. as in the first story linked above.
We currently use the ‘pre-chewed’ data (level 2), but MRSU would like to puta few years worth of southern ocean data through some new algorithms, hence the need for CHPC. A lot of the algorithms were written for northern waters, and the Benguela current has its own idiosyncrasies that might benefit from a fresh look.
This is correlated with field measurements - a research ship that goes to the areas of interest and samples the ocean for algae that produce the chlorophyll signature visible from space. That allows the level 2 data processing to more accurately reflect sea conditions.
Research at the CHPC
There is the Advanced Computing Engineering (ACE) Lab that looks at other computing technologies, like GPGPU and field programmable gate array boards. It is staffed by graduates from UCT.
How do you program a supercomputer ?
The first thing to check is to see if your problem is easily divisible into a lot of self-contained chunks. Ours is - data for one day does not affect other days except in God’s scheme of things.
Then the issue comes to be how you divide, and how you instruct them each to run the same program over different data. One way is to have a lookup table keyed by the hostname of the blade computer. Another way would be to have a central allocator to farm out the work jobs to blades as they become free.
There are other more sophisticated means. Matlab has long been a favourite of the scientific community, and Matlab have a parallel licence that allows commonly used matrix math on large datasets to be distributed over the blades.
I have been using python, and its NumPy and SciPy modules. These are optimised for single processors by, for instance, having core routines for Linear Algebra and Fourier Transforms written in FORTRAN. SciPy has a huge toolbox - with sparse matrices, signal processing, information theory. Python also has the MPI interface- a standardised way across languages to distribute your code across a computer cluster.
Update
Here is a later post on using the cluster.