Using the Centre for High Performance Computing, Cape Town
I have recently been contracting at the Centre for High Performance Computing. This is just an update on how to map the particular problem I have onto the computing cluster.
First steps
It is an explanation of how to get to the much easier job of splitting the main task up into bite-sized pieces that can be fed independently via a job submission system called MOAB.
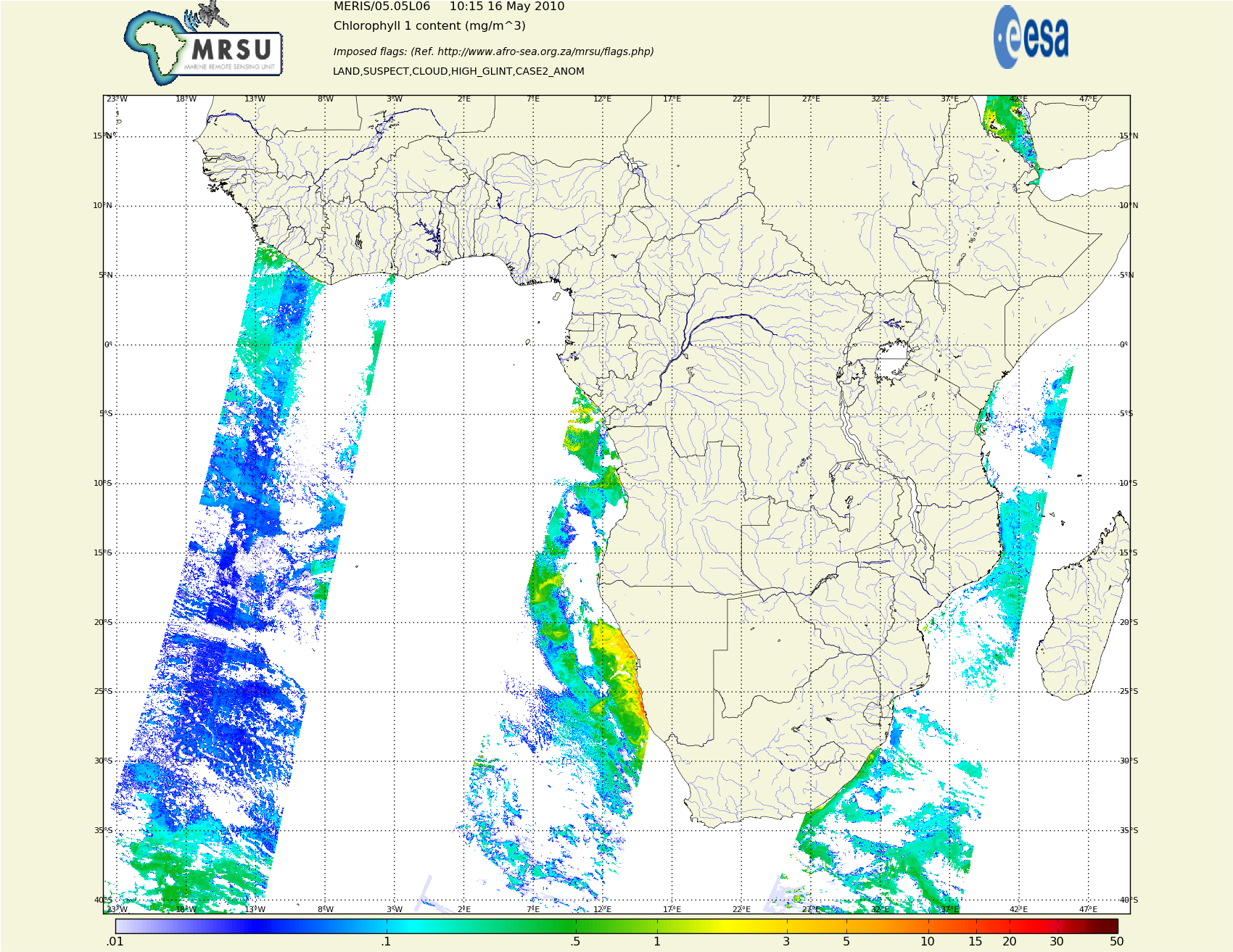
Task description
Each day satellites MODIS(NASA) and MERIS (ESA) do afew passes of a polar orbit over our region of interest, African coastal andinland waters. The (large amounts) of daily data arrive via a dedicated satellite link - about 1 Gig every day. They are in “swaths”, about 20 or so files from 10Meg to 800Meg.
We need to keep all this input data. It is a few terabytes and growing of several years of historical data.
This needs to be processed - mostly to cut it up and combine swaths to get smaller files of country-specific data, and a PNG picture of some attributes in the country netcdf file.
So I have a python script that reads the input files, brackets them by latitude and longitude, re-grids (lossily) the data onto a north-south grid as opposed to ‘along-track’ delivered data, writes the netcdf and png.
Collecting the data
All the input data was on a number of other machines in the oceanography department. The supercomputer cluster has four 79 terabyte cluster drives, accessible from all nodes. The network drives are themselves a distributed network of directory nodes and storage nodes, for speed and parallel access. See LUSTREfilesystems.
Each node runs linux, and can directly access these drives. For organisational purposes, I create a heirarchy of SATELLITE/YEAR/MONTH/* andcopy all the terabytes down.
Python
I will skip the off-topic but lengthy installation of python 2.6.5 on the NFS read-only share. Consider it done :)
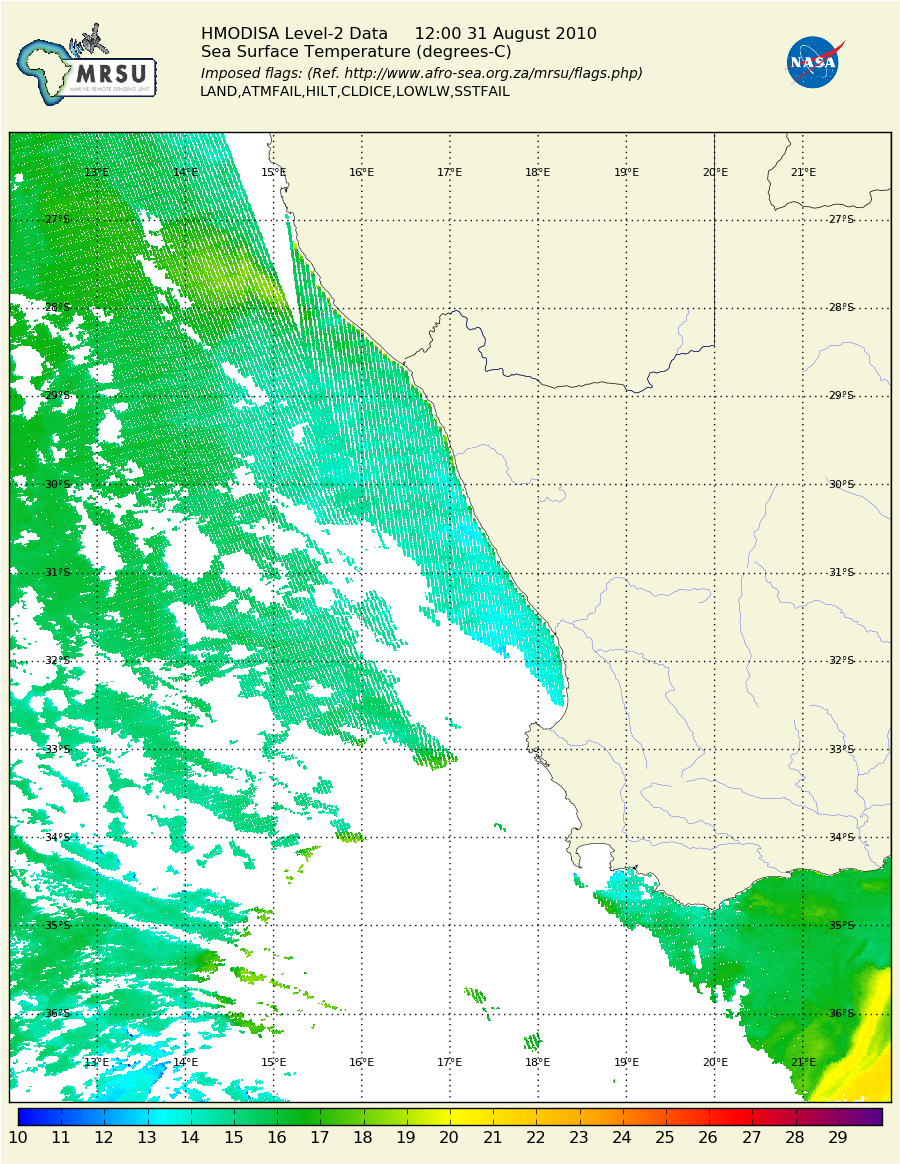
Sea surface temperature
I can now split the problem up by day, and satellite. I have a shell script that copies and decompresses a day’s input files to a ‘scratch’ area, and feeds that days-worth of files to a python program, which processes it repeatedly for each of our Regions of Interest, dropping the output files in the same directory. It can take up to about 6 hours to process a days files - mostly spent on the regridding operation.
You can see in this png of the Western coast of South Africa two separate swaths, and artifacts caused by the regridding operation at the lower resolution edges of the swath. MODIS orbits south to north, MERIS (above) the other way. Most of the gaps are clouds over the sea at the time of the satellite overpass.
MERIS have their own file format, but provide a java program to convert that to hdf5, a more widely recognised format that has python modules for input and output. Luckily the cluster has java :)
The shell script then copies the results back to a target file heirarchy, and deletes the input files, and finishes.
Firewall
The firewall setup around the computing cluster prevents any machine in the cluster from making network connections out. When logging into the cluster, you ’land’ on the login node, and from there you can ssh to any node in the clusteron its private 10.* Infiniband network. So copying the output data to the webserver must be orchestrated from outside.
MOAB
The product page talks about graphical installations and point and click, but I prefer the command line. Usually the GUI just pokes command line tools anyway, so you are closer to the metal as well as being convenient for remote use.
The submission tool, msub, takes as parameters a number of accounting switches, where to send script output (stdout and stderr), target blade classes, and a host of other things including my script.
A problem comes because I cannot pass parameters to the script on the command line. So, if I want to tell it which day to process, I have to use an environment variable.
There are ways of naming environment variables to be passed through, but now it is getting complicated. I chose to use the ‘jobname’ - a simple string available in the accounting switches that I can set to anything I like. I set it to the date - for instance “2010:02:29” is a leap-day.
You can embed all the msub switches (like expected job run time, feature set of target blades needed, stdin and stout) in the script itself, prefixed by"#MSUB", which is mighty convenient. so now submitting a day’s job becomes
msub -N 2010:08:11 ~/bin/meris.sh
and a trivial loop will do a month.
moab is probably sniggering at me for submitting so many single-threaded jobs and nothing more complex. I may even be penalised in the queue for jobs,but it works fine for me.
Loading and unloading
It is convenient to keep all the historical input data on the cluster filesystems, and that means setting up a daily job to rsync the satellite data as it arrives down to the cluster.
Output is currently served by the MRSU webserver at http://www.afro-sea.org.za/_ - and thus needs the data copied off the cluster to be served. Because of the difficulty of synchronising, I actually do the daily processing on a beefy desktop outside that is otherwise idle, just because all the network copying can be coordinated there, and I can use cron.
There is a plan to make the site more dynamic, where you could request a custom region, at which point I would consider poking the supercomputer cluster with long spoons from the webserver. First - we need users.
Users
This is a bit double-edged - probably the folks most interested in the daily information would be foreign fishing vessels :) Regardless, potentially interested parties must be made aware of this resource funded by the taxpayer.